渲染和送显
渲染
渲染由显卡(或 SoC)上的 GPU 完成,简单来说就是往后缓冲 (Back Buffer) 里哐哐哐干像素,一般要比后面的显示快得多, 当显示器还正在逐行扫描(Progressive Scanning)前缓冲(Front Buffer)时,后缓冲就覆盖前缓冲 (Buffer Swap), 屏幕就会出现撕裂 Tearing。
1 | static struct loader_dri3_buffer * |
dri3_alloc_render_buffer() 的任务是创建渲染 buffer (包括 front 或 back), 并向 X11 导出它们的 fd。驱动当然不是一下子把 buffers[] 数组填满, 它是"按需创建", buffers[] 像是提供这么多 buffer slot, 当 slot 后面是一个空闲的 buffer, 那就将它返回,否则才真正创建。
Drawable 和 Buffer
struct loader_dri3_drawable 和 struct loader_dri3_buffer 这两个结构体,一个作为 dri3_alloc_render_buffer() 的主要参数,一个作为它的返回值类型,可谓是了解 DRI3 扩展下的数据流的关键。
classDiagram
direction RL
m_loader_dri3_buffer o-- loader_dri3_buffer : LOADER_DRI3_NUM_BUFFERS
class loader_dri3_drawable {
+xcb_connection_t * conn
+xcb_screen_t * screen
+__DRIdrawable *dri_drawable
+xcb_drawable_t drawable
+xcb_window_t window
+int width
+int height
+int depth
+uint8_t have_back
+uint8_t have_fake_front
+uint64_t send_sbc
+uint64_t recv_sbc
+uint64_t ust
+uint64_t msc
+uint64_t notify_ust
+uint64_t notify_msc
+int cur_back
+int cur_num_back
+int max_num_back
+int cur_blit_source
+uint32_t *stamp
}
class m_loader_dri3_buffer {
+loader_dri3_buffer *buffers[5]
}
class loader_dri3_buffer{
+__DRIimage * image
+uint32_t pixmap
+__DRIimage * linear_buffer
+uint32_t fence
+xshmfence * shm_fence
+bool busy
+bool own_pixmap
+bool reallocate
+uint32_t num_planes
+uint32_t size
+int strides[4]
+int offsets[4]
+uint64_t modifier
+uint32_t cpp
+uint32_t flags
+uint32_t width
+uint32_t height
+uint64_t last_swap
}同步
- 当我们谈论 X client 和 server 之间的 Buffer 同步时是在说什么?
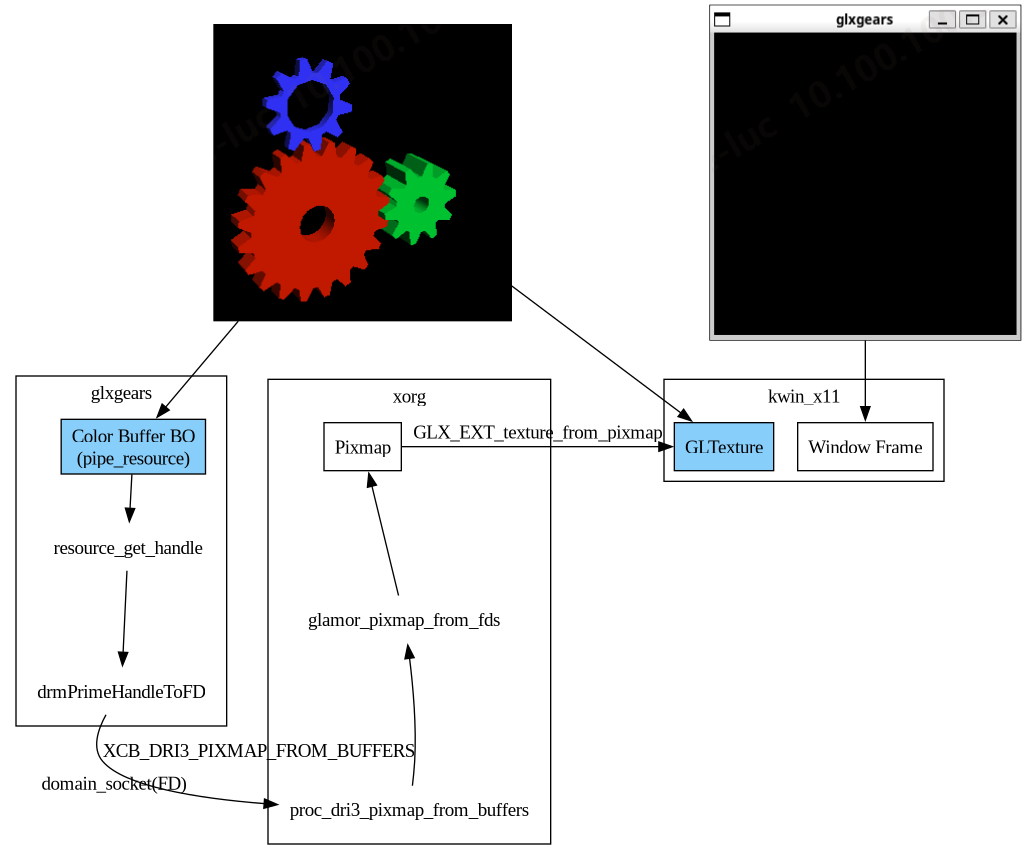
在DRI3扩展下, render buffer (BO作为GPU 的render target) 是一开始由X client (例如一个 3D App)创建的(可能不止一个), render buffer 创建好后随即会通过 __DRIimageExtension 的 queryImage() 查询到该buffer 的 FD (drmPrimeHandleToFD, 后面会将该 FD 传送给 X server), 而在 X 的 compositor, 拿到 GPU 的渲染结果实际上就是通过该 FD (drmPrimeFDToHandle) 将 render buffer gbm_bo_import() 到 X server 进程, 并创建X 的 Pixmap (Pixmap 的Backing BO就是当初App进程创建的)后读取渲染结果进行合成。
该过程通过 X client 和 server 进程间的 buffer 共享实现了 render buffer 的零拷贝。
而同步问题也在这个过程中产生,当 render buffer 被 server 进程导入后用于合成时,渲染结果什么时候被读取完毕(render buffer IDLE 状态),需要告知client 进程(client不能在上一帧数据未读取完毕前同时再渲染到同一个render buffer)。同样client 也须在 server 读取当前帧之前告知server 渲染是否已经完成。
这样 X client 和 server 之间的buffer 同步问题就产生了。
- xshmfence mapping to X SyncFence
xshmfence_alloc_shm()通过memfd_create()/shm_open()/open()之一系统调用返回一个共享内存文件描述符(fence_fd)xshmfence_map_shm(fence_fd)通过mmap()fence_fd 返回一个指向 struct xshmfence 的地址xcb_dri3_fence_from_fd()将这个 xshmfence 的 fence_fd 发送给 X server, 让其知道这个xshmfence 的存在
以上3步实际上是利用4个字节(sizeof(struct xshmfence))大小的共享内存在X server 和 client 进程间通过原子操作和 futex 系统调用达到两个进程对 render buffer 的同步访问。
(以上4个字节共享内存的结论是基于futex和原子操作实现的 xshmfence 的版本)
由于client 创建的render buffer 是与 X server 共享的,所以这个 render buffer 被两个进程读写时须要同步,Mesa3D 中是使用 xshmfence 来完成这个需求的。xshmfence 顾名思义它是基于共享内存的,采用它实现进程间对 render buffer 操作的同步,好处就是只需要将 xshmfence 映射到一个 X server SyncFence, 通过一个简单的函数调用(xshmfence_await(struct xshmfence *f))就可将调用进程(client process)阻塞直到 X server 完成对 render buffer的操作再被操作系统唤醒,而无需通过接收网络事件(socket event)来确定X server 是否已经完成对 render buffer 的使用。
导入/导出
render buffer 的导入/导出操作是Linux 下Buffer 共享和同步的一个标准流程,不仅仅是在 DRM 子系统使用,在Linux的其它子系统也广泛使用,如Video4Linux, Networking。这里仅仅将 mesa 中的实现与DMABUF 机制中的角色对应一下,作为一个DMABUF的应用案例分析。
-
导出(exporter·mesa)
(以上调到pipe_screen后以AMD Radeon驱动为例)
-
传送(FD transfer·xcb)
1
2
3
4
5
6static const xcb_protocol_request_t xcb_req = {
.count = 2,
.ext = &xcb_dri3_id,
.opcode = XCB_DRI3_PIXMAP_FROM_BUFFERS,
.isvoid = 1
}; -
导入(importer·xserver)
(不难看出如果驱动支持DRI3, 则有以下依赖关系 Xserver->Glamor->GBM)
-
mesa dri3 render buffer (DMABUF) Sharing
sequenceDiagram
autonumber
participant App
participant Mesa
participant X11
App-->>Mesa: eglMakeCurrent()
Mesa->>Mesa: dri_st_framebuffer_validate()
Mesa->>Mesa: dri2_allocate_textures()
Mesa->>Mesa: loader_dri3_get_buffers()
note left of Mesa: Return all necessary buffers and allocating as needed
Mesa->>Mesa: dri3_get_buffer()
rect rgb(191, 223, 255)
Mesa->>Mesa: dri3_alloc_render_buffer()
Mesa-->>X11: xcb_dri3_get_supported_modifiers()
X11-->>Mesa: xcb_dri3_get_supported_modifiers_reply()
Mesa->>Mesa: loader_dri_create_image()
Mesa->>Mesa: dri2_create_image()
Mesa->>Mesa: xxx_resource_create()
rect rgb(200, 150, 255)
Mesa->>Mesa: dri2_query_image_by_resource_handle(__DRIimage)
Mesa->>Mesa: xxx_resource_get_handle()
Mesa->>Mesa: xxx_bo_export()
note right of Mesa: Mesa 导出 FD
opt xcb_dri3_pixmap_from_buffers(buffer_fds)
Mesa-->>X11: xcb_send_requests_with_fds(buffer_fds)
end
end
rect rgb(200, 150, 255)
note left of X11: X11 导入 Buffer
X11->>X11: proc_dri3_pixmap_from_buffers()
X11->>X11: dri3_pixmap_from_fds()
X11->>X11: glamor_pixmap_from_fds()
alt GBM_BO_WITH_MODIFIERS
X11->>X11: gbm_bo_import(type=GBM_BO_IMPORT_FD_MODIFIER)
else
X11->>X11: gbm_bo_import(type=GBM_BO_IMPORT_FD)
end
end
end所有情况都是 Mesa (DRI client) 创建导出 RenderBuffer,X11 导入吗?
eglCreatePbufferSurface()
实际上 PBuffer 是离屏渲染使用的,它是由 X11 创建 buffer, X11 导出 FD, Mesa (应用进程) 导入作为伪前缓冲 (fake front buffer) 使用。
通常 eglCreate***Surface() 需要 App 先调用 XCreateWindow() 让 X11 创建 Pixmap, 但是 eglCreatePbufferSurface() 不用,它由 Mesa 调用 xcb_create_pixmap() 让 X11 创建 Pixmap, 之后 Mesa 再调用 xcb_dri3_buffers_from_pixmap() 让 X11 导出 Pixmap(gbm_bo) 关联的 FD, 由 Mesa 导入。
sequenceDiagram
autonumber
participant App
participant Mesa
participant X11
App-->>Mesa: eglCreatePbufferSurface()
rect rgb(191, 223, 255)
Mesa->>Mesa: dri3_create_surface(type=EGL_PBUFFER_BIT)
Mesa-->>X11: xcb_generate_id()
X11-->>Mesa: drawable ID (uint32_t)
Mesa-->>X11: xcb_create_pixmap()
App-->>Mesa: eglBindTexImage()
Mesa->>Mesa: dri_st_framebuffer_validate()
Mesa->>Mesa: dri2_allocate_textures()
Mesa->>Mesa: loader_dri3_get_buffers()
Mesa->>Mesa: dri3_get_pixmap_buffer()
rect rgb(200, 150, 255)
note left of X11: X11 导出 FD(调用 gbm_bo_get_fd(gbm_bo*))
Mesa-->>X11: xcb_dri3_buffers_from_pixmap()
X11-->>Mesa: xcb_dri3_buffers_from_pixmap_reply()
Mesa-->>X11: loader_dri3_create_image_from_buffers()
X11-->>Mesa: xcb_dri3_buffers_from_pixmap_reply_fds()
end
rect rgb(200, 150, 255)
note left of Mesa: Mesa 导入 Buffer
Mesa->>Mesa: dri2_from_dma_bufs2()
Mesa->>Mesa: dri2_create_image_from_fd()
Mesa->>Mesa: dri2_create_image_from_winsys()
Mesa->>Mesa: xxx_resource_from_handle()
Mesa->>Mesa: xxx_bo_import()
end
end- DRI2
DRI3 与 DRI2 的一个主要区别就是在 DRI3, RenderBuffer 是由 DRI client (Mesa) 创建后通过 bo_export() 导出其 DMA-BUF fd,由 X server 通过 proc_dri3_pixmap_from_buffers() 导入的。 而且 DRI2 不仅导入导出方面是反着的,而且 DRI client 导入的是 GEM name(不是 DMA-BUF fd), 据说 GEM name 这玩意虽然也可以在进程间传递,但相比 DMA-BUF fd 很不安全,所以新驱动都用 DMA-BUF fd 在进程间传递 Buffer, 只有旧驱动可能还有 GEM name。
实现上没太明白 GEM name 为什么不安全,大家都是 32-bit 整数,GEM name 能被猜,文件描述符 fd 也能被猜啊
找到解释了,PRIME Buffer Sharing - Overview and Lifetime Rules, 文件描述符 (file descriptor) 必须通过 UNIX domain sockets 在应用之间 send,不可能像全局唯一的 GEM names 一样被猜。 send over UNIX domain sockets 应该就是 XCB 库实现的这个函数 xcb_send_requests_with_fds()。
dri3_find_back
1 | /** |
dri3_find_back() 的任务是查找 buffers[] 中空闲 buffer 的 slot (array index), 如果存在,返回其 index, 否则等待 (dri3_wait_for_event_locked())
如何知道 buffer 是否空闲呢? buffer->busy, 这个标志在 SwapBuffers 时会置为 true, mesa 收到 IdleNotify 事件后置为 false
sequenceDiagram
autonumber
participant Mesa
participant X11
Mesa->>Mesa: dri3_find_back
note right of Mesa: 选取一个合适的空闲 slot id, buffers[id]有可能是空, 这时需要创建 buffer: dri3_alloc_render_buffer()
rect rgb(200, 150, 255)
note right of Mesa: mtx_lock()
alt pefer_a_different==false
Mesa-->>X11: dri3_flush_present_events()
loop xcb_poll_for_special_event
X11-->>Mesa: xcb_present_generic_event_t
end
Mesa->>Mesa: dri3_handle_present_event()
else perfer_a_different==true
Mesa-->>X11: xcb_flush()
loop dri3_wait_for_event_locked()
X11-->>Mesa: xcb_present_generic_event_t
end
Mesa->>Mesa: dri3_handle_present_event()
end
note right of Mesa: mtx_unlock()
endloader_dri3_swap_buffers_msc
1 | /** |
flowchart TB
subgraph Render ["渲染到 back buffer"]
direction TB
subgraph RenderBufferAlloc ["Allocate/Pick a back buffer"]
direction TB
a1["dri_make_current()"]
a2["st_api_make_current()"]
a3["st_framebuffer_validate()"]
a4["dri_st_framebuffer_validate()"]
a5["dri2_allocate_textures()"]
a6["dri_image_drawable_get_buffers()"]
a7["loader_dri3_get_buffers()"]
a8[["dri3_alloc_render_buffer()"]]
end
b["glDraw*()"]
end
A["eglSwapBuffers()"]
B["dri3_swap_buffers()"]
C["dri3_swap_buffers_with_damage()"]
D["glXSwapBuffers()"]
E["dri3_swap_buffers()"]
subgraph Swap ["loader_dri3_swap_buffers_msc()"]
direction TB
G["loader_dri3_vtable->flush_drawable()"]
H["dri3_find_back_alloc()"]
I["dri3_flush_present_events()"]
J["xcb_xfixes_create_region()"]
K["xcb_xfixes_set_region()"]
L["xcb_present_pixmap()"]
M["dri_invalidate_drawable()"]
end
subgraph Note1 ["返回要送显的 back buffer"]
dummy1["这里通过 dri3_find_back()<br>确保这里返回的是当前已经渲染好的(flushed) back buffer"]
end
subgraph Note2 ["选取或申请 back buffer"]
dummy2["loader_dri3_drawable->buffers[]有5个<br>loader_dri3_buffer 的槽位<br>第1帧渲染时需要调用<br>dri3_alloc_render_buffer()<br>来申请新的back buffer"]
end
a1 --> a2 --> a3 --> a4 --> a5 --> a6 --> a7 --> a8 --> b
b --> A
b --> D
A --> B
B --> C
D --> E
C --> G
E ---> G
G --> H --> I --> J --> K --> L --> M
Note1 -.-> H
Note2 -.-> a8DRI2 Throttle
这个扩展原来好像是控制 DRI client 能同时并发地渲染多少个 RenderBuffer (或者说多少帧)的,因为原来 mesa 里有一个 PIPE_CAP_MAX_FRAMES_IN_FLIGHT, 因为这个值后来要么是 1, 要么是 0,就被改成 PIPE_CAP_THROTTLE 了, 默认是 throttle 的, 按目前的实现,如果节流了,就是说当驱动提交了第 2 帧的渲染命令后,要等第 1 帧渲染完成 (pipe_fence_handle 是 drm_syncobj 的封装),才能继续准备第 3 帧的渲染命令。
flowchart LR
subgraph "Frame 0"
F1["CPU Submit 1"]
end
subgraph "Frame 1"
F2["CPU Submit 2"]
R1["GPU Render Done 1 fa:fa-spinner"]
end
subgraph "Frame 2"
F3["CPU Submit 3"]
R2["GPU Render Done 2 fa:fa-spinner"]
end
subgraph "Frame 3"
F4["CPU Submit 4"]
R3["GPU Render Done 3 fa:fa-spinner"]
end
F1 --> F2
F2 --Block until--> R1 --> F3
F3 --Block until--> R2 --> F4
F4 --Block until--> R3Throttle 的效果是 CPU 在提交后一帧的渲染命令后,要等(所谓“等”就是主线程调用 drmSyncobjWait() 阻塞)前一帧渲染完成后才唤醒继续准备下一帧数据,整个过程实际上是节流 CPU, 是让生产者-消费者中的生产者(CPU) 慢一点。所以 DRI2 Throttle 的本意就是在 GPU 渲染任务比较重(延迟大)的时候,CPU 这边没必要“玩命”准备数据,否则反而会导致比如过多消耗显存等其它问题。
Mesa 中对 Throttle 的实现很有技巧性。因为这里“等”的是上一帧数据提交给内核后,drm_gpu_scheduler 为这个 job 创建的一个 dma_fence, 在提交时,userspace 会给 kernel 一个 syncobj (当一个 fence 容器用,意思是 gpu scheduler 创建好 fence 后 attach 到这个 syncobj, userspace 就可以通过 drmSyncobjWait() 阻塞式地等 syncobj 包含的 fence 是否被 signaled)。 因为 fence 是在渲染命令 push 到 drm_gpu_scheduler 后内核才创建的, 所以提交时带下去的 syncobj 用来装当前产生的 fence,如果你需要在下一帧数据提交后等上一帧的 fence, 你需要在当前帧提交后,创建一个新的 syncobj 来存当前帧的 fence,这样就可以在下一帧提交后, 用这个新的 syncobj 来等上一帧的 fence 了。 相当于同一个 fence 放在两个不同的容器里用。
送显
如果平台的窗口系统(Winsys)是X11, 则送显主要是通过 Present 扩展完成的。Client (代码主要在 UMD) 与 X Server 的交互主要通过 present_event 完成的, present_event 主要有以下 3 个:
- XCB_PRESENT_EVENT_CONFIGURE_NOTIFY
- XCB_PRESENT_EVENT_COMPLETE_NOTIFY
- 这个事件传达的主要信息是 X Server 是以哪种模式上屏刚才送显的 Back Buffer 的(注意是过去完成时), 主要有 4 种模式
- XCB_PRESENT_COMPLETE_MODE_COPY
- 几乎所有的 3D 应用(除了像 KWin 这样的 compositor)在绝大多数情况下送显的 Back Buffer 都是以这种模式上屏的。因为一般的应用不是全屏,不可能直接FLIP (改一下 DC Framebuffer base register)
- XCB_PRESENT_COMPLETE_MODE_FLIP
- 像 KWin 合成器合成的全屏 screen image 上屏一般是这种模式,这种方式显然要比 COPY 快很多
- XCB_PRESENT_COMPLETE_MODE_SKIP
- 如果 PresentCompleteNotify 传回的是这个模式,不好意思,X Server 并没有把刚才送显的 Back Buffer 上屏,这意味着丢帧
- XCB_PRESENT_COMPLETE_MODE_SUBOPTIMAL_COPY
- 如果 PresentCompleteNotify 传回的是这个模式,表明如果下次用不同的 format/modifier 重新申请一个 Back buffer,X Server 很可能就可以以 FLIP 模式上屏 Back buffer
- XCB_PRESENT_COMPLETE_MODE_COPY
- 这个事件传达的主要信息是 X Server 是以哪种模式上屏刚才送显的 Back Buffer 的(注意是过去完成时), 主要有 4 种模式
- XCB_PRESENT_EVENT_IDLE_NOTIFY
1 | typedef struct present_event { |
-
注册事件
dri3_setup_present_event(struct loader_dri3_drawable *draw)xcb_present_select_input(): 告诉Xserver,client 正在监听哪些事件。(注册时实际上是使用对应事件的 MASK 注册的,因为在向 Xserver 发送的注册消息中,注册的所有消息的MASK ORing 在一个 uint32_tevent_mask发送过去的)
-
接收事件
dri3_setup_present_event(struct loader_dri3_drawable *draw)xcb_register_for_special_xge(): 创建一个接收Present XGE 事件的队列,实质上是初始化了一个 pthread_cond_t。(这里 special 就special在它是一个带了条件变量的 generic events 的队列)1
2
3
4
5
6
7
8
9
10
11struct xcb_special_event {
struct xcb_special_event *next;
uint8_t extension;
uint32_t eid;
uint32_t *stamp;
struct event_list *events;
struct event_list **events_tail;
pthread_cond_t special_event_cond;
};
(XGE指 X Generic Event extension)
-
处理事件
-
等待事件 (阻塞式)
loader_dri3_wait_for_msc(): (阻塞)等待X Server 管理的 MSC 大于等于当前应用的 MSC (target_msc)loader_dri3_wait_for_sbc(): (阻塞)等待SBC 大于等于当前应用的 SBC (target_sbc)
以上无论是 loader_dri3_wait_for_msc() 还是 loader_dri3_wait_for_sbc(), 当所等待的条件满足后,都会更新(dri3_handle_present_event())当前client 的状态(UST, MSC, SBC), 整个过程是一种同步,也是一种协商。
Vertical Refresh vs Swap Interval
这两个概念在渲染和送显这整个过程里很重要。它们俩是两个层次的东西,简单说,前者是硬件层面的,后者是软件层面的。
Vertical Refresh (又叫 Vertical Refresh Rate, Vsync Rate), 指显示器一秒钟能刷新多少次画面。给定一款显示器,它支持的 Vertical Refresh Rate 就那么几种,比如设置成 60 Hz, 表示每 16.67ms 刷新一次。
Swap Interval 是图形 API (EGL/GLX) 提供的一个功能 (GLX_SGI_swap_control, GLX_EXT_swap_control, GLX_MESA_swap_control),就是允许应用程序渲染时自己选择跟不跟显示器这个刷新节奏,通常 Swap Interval 是一个整数值
| Swap Interval | 描述 | 最大 FPS |
|---|---|---|
| 0 | 不跟 Vsync, 尽可能提交,但可能撕裂 | 取决于 GPU 性能 |
| 1 | 每 Vsync 提交一次 | 等于 vsync rate |
| 2 | 每两次 Vsync 提交一次 | vsync rate 的一半 |
NOTE: EGL 是通过 eglSwapInterval() 设置 Swap Interval 的, Vulkan 不直接设置 interval 值,而是通过 VkPresentModeKHR
DRM Modifiers
向 X server 查询并获取显示/渲染设备所支持的 modifiers 是执行 __DRIimageExtension::createImage() 的一个准备工作。但 createImage() 允许modifiers 为空,此情况下让驱动来选一个合适的纹理图像内存布局。
1 | __DRIimage * |
与 X server 交互的过程包括 3 步:
xcb_dri3_get_supported_modifiers(draw->conn, draw->window, depth, buffer->cpp*8): 返回一个 cookiexcb_dri3_get_supported_modifiers_reply(draw->conn, mod_cookie, &error): 返回一个 reply 包含实际的modifiers内容xcb_dri3_get_supported_modifiers_reply_t
1
2
3
4
5
6
7
8
9typedef struct xcb_dri3_get_supported_modifiers_reply_t {
uint8_t response_type;
uint8_t pad0;
uint16_t sequence;
uint32_t length;
uint32_t num_window_modifiers;
uint32_t num_screen_modifiers;
uint8_t pad1[16];
} xcb_dri3_get_supported_modifiers_reply_t;proc_dri3_get_supported_modifiers(ClientPtr client)-
dri3_get_supported_modifiers(): 通过drm_format_for_depth(depth, bpp)获得一个DRM_FORMAT_*, 实际上drm_format_for_depth()返回的format也只会是以下4种之一:1
2
3
4DRM_FORMAT_RGB565 // bpp = 16
DRM_FORMAT_XRGB8888 // bpp = 24
DRM_FORMAT_XRGB2101010 // bpp = 30
DRM_FORMAT_ARGB8888 // bpp = 32无论是获取 screen_modifiers 还是 window_modifiers, 实际上都依据 format 获取相应的 modifiers.
glamor_get_drawable_modifiers(DrawablePtr draw, uint32_t format, uint32_t *num_modifiers, uint64_t **modifiers): 回调由具体的DDX(如modesetting)提供的get_drawable_modifiers()函数
-
xcb_dri3_get_supported_modifiers_window_modifiers(mod_reply)xcb_dri3_get_supported_modifiers_screen_modifiers(mod_reply): 如果获取window_modifiers 失败则fallback 到screen_modifiers
参考
- MSC: Graphics Media Stream Counter, 实际上就是CRTC 的Vblank中断次数 (GLX_OML_sync_control)
- SBC: Swap Buffer Counter, 就是Swapbuffer 的次数 (GLX_EXT_swap_control)
- GEM Objects Naming
- Implement a throttle dri extension v2
- 【B站】全网最详细易懂的Gsync Freesync 垂直同步工作原理科普