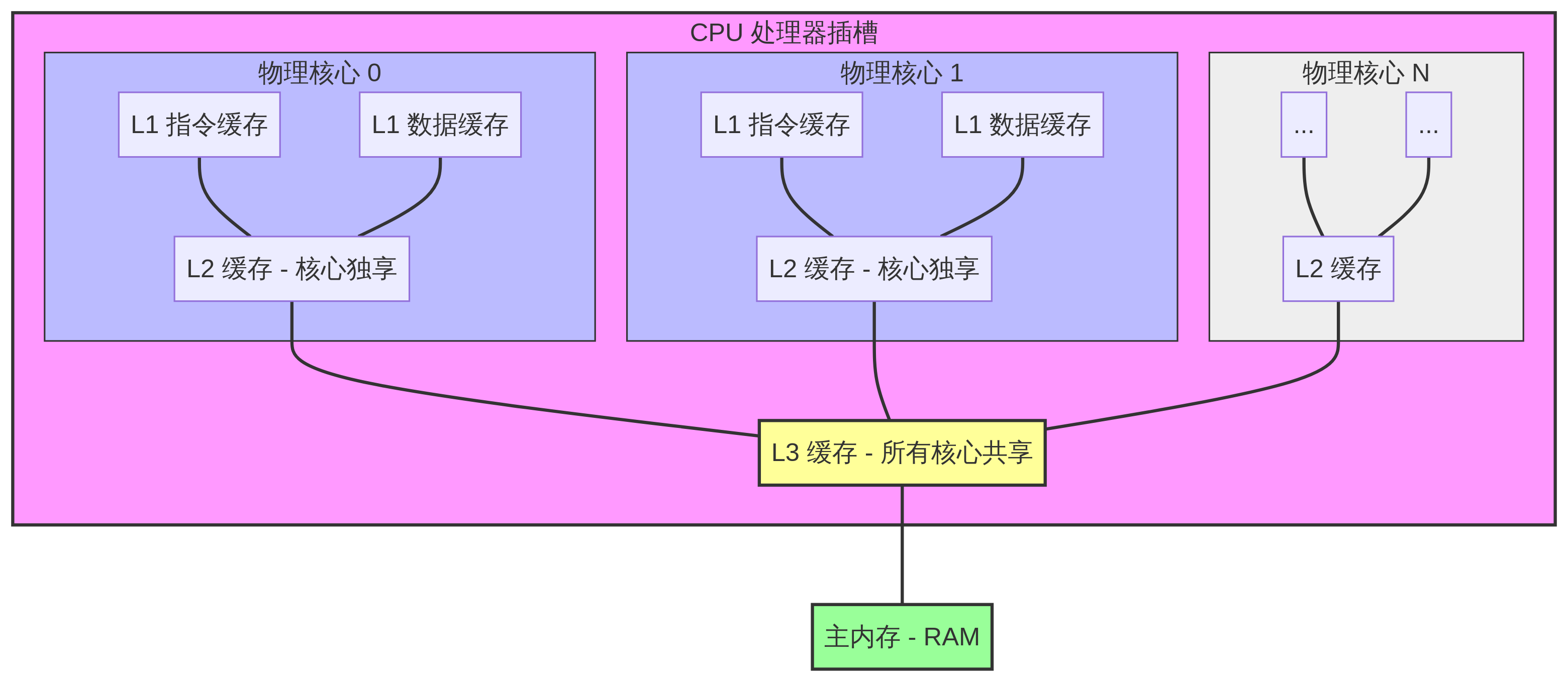
音同 cash, 不管是在硬件还是软件都是影响性能的一个重要因素之一。Cache 无论是 CPU cache 还是 GPU cache 一般都分级, L1,L2, 在 Multi-processor CPU/GPU 架构中, L1 一般是分开的,每个核心(Core)有自己的 L1 Cache, 而 L3 Cache 是同一处理器插槽(Socket)上的所有物理核心共享的, L2 Cache 是每核心私有还是所有核心共享和处理器的微架构有关。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Address sizes: 39 bits physical, 48 bits virtual Byte Order: Little Endian CPU(s): 12 On-line CPU(s) list: 0-11 Vendor ID: GenuineIntel Model name: Intel(R) Core(TM) i5-10505 CPU @ 3.20GHz CPU family: 6 Model: 165 Thread(s) per core: 2 Core(s) per socket: 6 Socket(s): 1 Stepping: 3 BogoMIPS: 6384.02 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology cpuid pni pclmulqdq vmx ssse3 fma cx16 pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi ept vpid ept_ad fsgsbase bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves md_clear flush_l1d arch_capabilities Virtualization: VT-x Hypervisor vendor: Microsoft Virtualization type: full L1d cache: 192 KiB (6 instances) L1i cache: 192 KiB (6 instances) L2 cache: 1.5 MiB (6 instances) L3 cache: 12 MiB (1 instance) Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled Vulnerability L1tf: Not affected Vulnerability Mds: Not affected Vulnerability Meltdown: Not affected Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT Host state unknown Vulnerability Retbleed: Mitigation; Enhanced IBRS Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence Vulnerability Srbds: Unknown: Dependent on hypervisor status Vulnerability Tsx async abort: Not affected
不管 Cache 有多少级,反正是为了降低 processor 访问 memory 的时延的。但是另一方面,当数据缓存到 Cache 中后,就必然引出一致性问题,这里的一致性应该有两个方面
各个 processor 看到的 cache 里的内容一致
cache 与 memory 里的内容一致
注:“内容一致”的另一种说法是“数据是不是最新的”,
Write-Combining 是 X86-64 平台上一种特殊的内存类型 (Memory Type), 它被广泛应用在 X86-64 平台的 I/O 和其它各种外设的交互中。它的主要含义是将多个 stores (写内存) 收集到 burst transactions中 ,所以它主要是为了优化 CPU 访存(写)的效率。
同样的想法和技术在不同的平台下,只是叫法不同。Arm 平台自然也有类似的优化技术,即 GRE (Gathering, Reordering, Early write acknowledgement), Arm 架构定义了两种不使用 Cache (Non-Cacheable ) 的内存类型
Normal Non-Cacheable (Normal NC)
Device memory with GRE attributes (Device-GRE)
这两种内存类型的共同点是:
不使用 Cache
支持 GRE (相当于支持 Write-Combining)
下表将 X86-64, Arm Normal NC, Arm Device-GRE 做了一个对比
X86-64
Arm Normal NC
Arm Device-GRE
Relaxed Order
Yes
Yes
Yes
Gathering
Yes
Yes
Yes
Read Speculation
Yes
Yes
No
Unaligned Access
Yes
Yes
No
Gathering Size
64 Bytes
micro-arch
micro-arch
注:micro-arch 的意思是具体大小取决于具体微架构设计
从上表可以看出,Arm 的 Normal NC 等同于 X86-64 的 WC, 而 Arm 上的两种非 cache 的内存的主要区别在读预测和非对齐访问,实际上,个人理解 Arm Device-GRE 之所以会存在只是因为"读预测" 和 “非对齐访问” 这两种特性在 Arm 架构下本来就不常用 , 单就优化 CPU 写内存来说,它俩并不是什么影响因素。