Buffer Sharing and Synchronization
DMA-BUF
flowchart BT
App@{ img: "/images/dma-buf/window-content.png", label: "vram for rendering", pos: "d", w: 60, h: 60, constraint: "on" }
Window@{ img: "/images/dma-buf/window-frame.png", label: "vram for window frame", pos: "d", w: 60, h: 60, constraint: "on" }
subgraph app [glxgears]
BO_10
end
subgraph x11 [Xorg]
BO_20
BO_11
end
subgraph compositor [kwin_x11]
BO_21
end
App ~~~ BO_10 --Exporter--> App
App --Importer--> BO_11
Window ~~~ BO_20 --Exporter--> Window
Window --Importer--> BO_21DMA-BUF 是 Linux 内核驱动中在上下文间,进程间,设备间,子系统间共享 buffer 的一种机制。 大概在内核 3.2 版本就实现了。 按最初的设计文档描述的,该框架大致是这样的:
- 导出者创建一个固定大小的 buffer object, 并将一个 struct file(anon file) 和 allocator 定义的一组操作(map/unmap/cache-sync 等等) (
struct dma_buf_ops) 与之关联 - 不同的设备调用
dma_buf_attach()将自己加到 buffer object 的 attachments 列表, 因为一个 buffer object 可以供多个设备(importers)使用 - 这个导出的 buffer object 在各种实体间通过共享文件描述符 fd 来共享
- 收到 fd 的导入者将重新获取到 buffer object, 使用导出时关联的
dma_buf_attach_ops去访问这个 buffer - 导出者和导入者使用
map_dma_buf()和unmap_dma_buf()来共享 buffer object 的 scatterlist
struct dma_buf 是一种胶水结构, 它将一个 anonymous file 和一个 drm_gem_object 以及导出者需要实现的一组对这个 buffer 的一组操作 dma_buf_ops 等等粘合在一起
1 | struct dma_buf { |
以 glxgears(PRIME_HANDLE_TO_FD) 和 Xorg(PRIME_FD_TO_HANDLE) 之间的共享过程为例, 主要有两个主要问题:
- 要给 DMA-BUF 套一层匿名文件(Anonymous File), 这样才可以安全地在进程间共享
- 导入后,导入进程新建的 GPU 虚拟显存地址到物理显存地址的映射要能够映射到与导出侧相同的 GPU 物理显存地址 (GPU VA 倒无所谓)
内核在 drm_file 下搞了一个 dmabuf 和 handle 的红黑树作为 DMA-BUF 缓存, 这样在同一设备文件中的导出导入或同一个 drm_gem_object 被同一个设备多次导入的情况就会高效一些。
1 | /** |
这个 import/export caches 有几个必要的作用:
- 保证对于任意一个 drm_gem_object 总是有一个唯一的用户态 handle (见 Piglit: ext_image_dma_buf_import-refcount-multithread)
- 可以允许 UMD 去检测重复的导入
struct file, struct drm_file, struct drm_prime_file_private 三者的关系是
erDiagram
file ||--|| drm_file : contains
file {
atomic_long_t f_count
spinlock_t f_lock
fmode_t f_mode
file_operations *f_op
address_space *f_mapping
void *private_data
}
drm_file ||--|| drm_prime_file_private : contains
drm_file {
TYPES others
drm_prime_file_private prime
}
drm_prime_file_private {
mutex lock
rb_root dmabufs
rb_root handles
}导入/导出的实现
flowchart LR
subgraph export ["Export"]
direction TB
1a["drmPrimeHandleToFD()"]
1b["DRM_IOCTL_PRIME_HANDLE_TO_FD"]
1c["drm_prime_handle_to_fd_ioctl()"]
1d["drm_gem_prime_handle_to_fd()"]
1e["drm_gem_prime_handle_to_dmabuf()"]
1f["export_and_register_object()"]
end
subgraph import ["Import"]
direction TB
2a["drmPrimeFDToHandle()"]
2b["DRM_IOCTL_PRIME_FD_TO_HANDLE"]
2c["drm_prime_fd_to_handle_ioctl()"]
2d["drm_gem_prime_fd_to_handle()"]
2e["drm_prime_lookup_buf_handle()"]
2f["drm_gem_prime_import()"]
end
1a --> 1b --> 1c --> 1d --> 1e --> 1f
2a --> 2b --> 2c --> 2d --> 2e --> 2f
export --> importstruct file, struct dma_buf 的关系
- 导出者
DRM_IOCTL_PRIME_HANDLE_TO_FD
先拿这个 gem_handle 去红黑树里找 dma_buf (drm_prime_lookup_buf_by_handle()), 如果有就返回这个 dma_buf,如果没有就调用 export_and_register_object() 给对应的 drm_gem_object 新申请一个 struct dma_buf,再由内核把这个 gem_handle 和 dma_buf 都缓存到红黑树中 (drm_prime_add_buf_handle()), 最后 fd_install(fd, dmabuf->file); 把 fd 返回用户态的导出者。
1 | /** |
- 导入者
DRM_IOCTL_PRIME_FD_TO_HANDLE
导入者接收到底层透过 UNIX domain socket 传来的 prime_fd 后 (如 Xorg 通过 proc_dri3_pixmap_from_buffers() 接收),通过 DRM_IOCTL_PRIME_FD_TO_HANDLE IOCTL 陷入内核态,内核通过 dma_buf_get(prime_fd) 直接找到对应的 DMA-BUF, 然后先去 DMA-BUF 缓存中找 (drm_prime_lookup_buf_handle()),如果命中就直接将 handle 返回给导入者, 如果不命中,就调用 drm_gem_prime_import_dev() 来完成 DMA-BUF Sharing 中最最关键的操作:当 Buffer 导入另外一个进程后,这个 Buffer 的 GPU Mappings (GPU pagetables) 怎么复制过来。
1 | /** |
Dynamic DMA-BUF Mapping 和 Cached Sg Table
sg_table 是描述不连续的物理内存块(这个内存块是以物理页为单位的)的表结构,就是 scatterlist 的数组。
1 | struct scatterlist { |
page_link保存的是struct page *, 即物理页的结构体指针再加最低两位的两个标识位dma_address在有 IOMMU 的系统中是一个 I/O 虚拟地址(下图中的 Z),在没有 IOMMU 的系统中就是设备地址空间(或 DMA 地址空间)的物理地址(下图中的 Y)
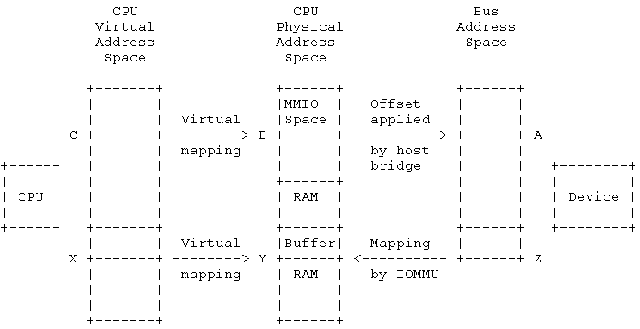
dma_direct_map_sg()
dma_direct_map_sg() 是由一个 scatterlist 对应的物理页得到对应的 dma_address, 就是上图中 Y 到 Z 的映射
flowchart LR
A["struct scatterlist *"]
B["struct page *"]
C["phys_addr_t phys"]
D["sg->dma_address"]
A -- sg_page() --> B -- page_to_phys() --> C -- phys_to_dma() --> Ddma_fence
struct dma_fence 是一个类似 struct completion 的结构体,用来跟踪 GPU 任务,当一个 GPU 任务结束时,对应的 dma_fence 被 signaled.
dma_fence_default_wait 是 dma-fence 默认的 wait 操作。该函数会让当前进程(task) 进入睡眠状态 (可中断睡眠或不可中断睡眠,取决于调用者传入的参数 intr), 直到 dma-fence 被 signaled 或者设置的超时时间到。
1 | cb.base.func = dma_fence_default_wait_cb; |
dma_resv
dma_resv (reservation object) 是一组 dma_fence + 一个锁,当调用者通过 dma_resv_add_fence() 向 dma_resv 里加入新的 dma_fence 时需要持有这个锁。
- 描述对
dma_resv不同的使用场景 - 在调用
dma_resv_get_fences()时,决定哪些 fences 被返回
flowchart TD
subgraph gem [drm_gem_object]
D[dma_buf]
subgraph _resv ["struct dma_resv _resv"]
_F@{ shape: docs, label: "dma_fence"}
end
RP["struct dma_resv *resv"]
end
B@{ shape: lin-cyl, label: "dma_buf"}
subgraph resv [dma_resv]
F@{ shape: docs, label: "dma_fence"}
end
D --> B --> resv
RP --except for imported GEM objects--> _resv- 为什么同一个
dma_buf会有那么多dma_fence与之关联呢?
因为同一个 Buffer 会有多个使用者, 有的读,有的写,有的等,这个 Buffer 的所有使用者的每个操作,理论上都有一个 dma_fence, 这些 dma_fence 在这整个机制下“有条不紊”地被 signaled, 才能保证所有访问都是按预期的顺序发生,这就是同步(每个使用者都可能是并发的进程)。
Synchronization
隐式还是显式同步的主要区别在于同步是否由应用 (Applications) 直接控制,Vulkan 以前的图形 API,同步是由内核驱动或用户驱动完成的,应用完全不参与,这就是所谓的 “Implicit Synchronization”, Vulkan 中,同步完全是由应用控制的,哪个渲染任务等哪个渲染任务,CPU 什么时候等 GPU, 都是由应用直接控制,从这一点也说明 Vulkan 应用是比较难写的,但 Vulkan 驱动(尤其用户驱动) 相对简单一些。但是问题是,不是所有的图形应用都是 Vulkan 写的 (Xorg, Wayland compositor 都不是 Vulkan 写的,而好多 Wayland client 可能是 Vulkan 写的),所以目前还需要一些其它方案解决这种隐式同步和显式同步共存的场景。Explicit sync 这篇博文关于这两者的概念讲得很清楚,这里主要是从实现的角度,做一下自己学习理解隐式同步和显式同步的记录。
Implicit Synchronization
所谓隐式同步,就是驱动 (KMD) 会在每个 dmabuf 以及 buffer object 上附加一个 dma_fence, 以确保渲染命令的有序执行,以及 buffer 是否已经准备就绪后才可让消费者进行读取,所有这些工作基本上在内核完成,完全不需要应用程序的干预。这种方案虽然简单(对于应用开发者)来说,但会有过度同步 (Over-Synchronization) 的问题。
Explicit Synchronization
- sync_file
CONFIG_SYNC_FILE 是内核 3.10 引入的一个可配置的 (configurable) 配置选项, 它控制的是 Linux 内核 Explicit Synchronization Framework 的编译。Sync File Framework 增加了由用户空间控制的显式同步, 它提供了通过用户空间组件 (Wayland, Vulkan 等)在驱动之间以 Sync File 文件描述符形式的 struct dma_fence 向用户空间的收发能力。Sync File 的主要使用者是 GPU 和 V4L 驱动, 它们通常会将一个 dma_fence 关联到一个 dmabuf, 这是隐式同步的做法, 而现在驱动会将与 dmabuf 相关的这个 dma_fence 以 Sync File FD传送到用户空间。
NOTE: sync file 最初是先在 Android kernel 内实现的
这里我们可以将 struct drm_syncobj 和 struct drm_gem_object 做个对比, 何其相似!
- drm_syncobj
flowchart LR
A[file descriptor]
B[dma_fence]
A -- SYNCOBJ_FD_TO_HANDLE<br>drmSyncobjFDToHandle() --> B
A <-- drm_syncobj --> B
B -- SYNCOBJ_HANDLE_TO_FD<br>drmSyncobjHandleToFD() --> A- drm_gem_object
flowchart LR
A[file descriptor]
B[dma_buf]
A -- PRIME_FD_TO_HANDLE<br>drmPrimeFDToHandle() --> B
A <-- drm_gem_object --> B
B -- PRIME_HANDLE_TO_FD<br>drmPrimeHandleToFD() --> A- drmSyncobjCreate()
1 | extern int drmSyncobjCreate(int fd, uint32_t flags, uint32_t *handle); |
drm_syncobj 在用户空间只是一个 32 位整数 (handle), 创建它的用户态接口接受两个入参,一个出参:
- fd: drm 设备节点打开后的文件描述符
- flags: 要么 0, 要么
DRM_SYNCOBJ_CREATE_SIGNALED - handle: 由内核返回的代表新创建的 drm_syncobj 的 ID 存放在 handle 这个地址
再看看创建 syncobj 的内核态接口,它里面有两步:
- drm_syncobj_create()
仅仅是申请 struct drm_syncobj 的内存, 初始化它的数据成员, 而且最关键的成员 dma_fence 还是空的,当用户传入 DRM_SYNCOBJ_CREATE_SIGNALED 标志时,drm_syncobj_create() 会自己创建一个 stub fence 赋给这个 syncobj, 如果创建时标志是 0, 则由用户后面绑定相关的 dma_fence (当然还是通过 syncobj 的形式,因为 dma_fence 对用户态不可见, 一般是用 drmSyncobjExportSyncFile(), drmSyncobjCreate(), drmSyncobjImportSyncFile() 来完成的。)
- drm_syncobj_get_handle()
返回的这个 32 位整数代表的就是 drm_syncobj, 但它仍然不是文件描述符 fd, 最终要让 drm_syncobj 能有一个真正的文件描述符还需要两个 IOCTL:
DRM_IOCTL_SYNCOBJ_HANDLE_TO_FDDRM_IOCTL_SYNCOBJ_FD_TO_HANDLE
感觉为了让用户空间能够直接操作 dma_fence 这个内核的同步原语,费了“好大劲”,这背后应该有系统设计层面的考虑,后面有时间再琢磨。
1 | /** |
FD to Handle Convert
int drmSyncobjFDToHandle(int fd, int obj_fd, uint32_t *handle);int drmSyncobjHandleToFD(int fd, uint32_t handle, int *obj_fd);
Sync File Transfer
int drmSyncobjImportSyncFile(int fd, uint32_t handle, int sync_file_fd);int drmSyncobjExportSyncFile(int fd, uint32_t handle, int *sync_file_fd);
drmSyncobjFDToHandle() 和 drmSyncobjImportSyncFile() 的区别仅仅是后者设置了 DRM_SYNCOBJ_FD_TO_HANDLE_FLAGS_IMPORT_SYNC_FILE 这个 flags。drmSyncobjHandleToFD() 和 drmSyncobjExportSyncFile() 也是类似。
drmSyncobjExportSyncFile() 通过 ioctl 将用户给定的 syncobj ID 转换成一个文件描述符返回给用户。而 SyncobjExport/ImportSyncFile 这对操作和 SyncobjFDToHandle/HandleToFD 这对操作的区别是后者是给同一个 drm_syncobj 提供两个不同的 ID 而已。
而前者通过和 drmSyncobjCreate() 配合,会产生另外一个新的 drm_syncobj
Questions
- syncobj 的 handle 可以是 0 吗?
不会是 0
drm_syncobj_get_handle() 和 drm_gem_handle_create_tail() 一样,是通过 idr_alloc() 申请的一个给定范围内的 32 位整数,
1 | ret = idr_alloc(&file_private->syncobj_idr, syncobj, 1, 0, GFP_NOWAIT); |
它申请范围在最小值是 1 (包含)和最大值是 0 (不包含,实际上最大值是 0xffffffff) 之间的一个整数。
这里主要根据内核邮件列表里的一个讨论来更好的理解 dma-buf 的设计思路和使用原则。
-
对于 dma-buf 来说, 什么是 static attach ? 什么是 dynamic attach ?
- static attach 应该是指 dma-buf 对应的 page 不会在内存中移动 (move), 而 dynamic attach 相反有可能移动
-
用户为什么不直接将 dma-buf 的 PFN (物理页帧号) 共享给 importer, 让 importer 自己去创建 mappings ?
- dma-buf 设计的就是不把
struct page或 pfn 暴露给 importer, 本质上, dma-buf 只传送 dma_addr。所以 mappings 总是由 exporter 创建,而不是由 importer。 - exported buffer 未必一定是内存 (有
struct page), 也可能是 MMIO
- dma-buf 设计的就是不把
-
但为什么一定要让 exporter 去 map 呢?
-
Exporter mapping 存在问题的场景:
- Private address space
- Multi-path PCI
- Importing devices need to do things like turn on ATS on their DMA
- TPH bits needs to be programmed into importer device
- iommufd and KVM
-
为什么把 dma-buf 的 backing storage 信息暴露给 importer 是一个坏主意?
-
exporter 会获取 importer 的
struct device -
multipath 总是需要在 importer 侧有额外的元信息去告诉 device 选择哪个 path
😦 这5个场景目前一个都不知道是干什么的 😦