CUDA Thread Hierarchy vs OpenGL Compute Shader Thread Hierarchy
Contents
CUDA Thread Hierarchy

CUDA中的kernel是一段可在GPU独立运行的小程序,而且这段程序会被实例化(类似的说法还有launched, issued, executed, invoked)成非常多的thread, 这些线程可并发地在GPU上运行。程序员或者说编译器将这些线程组织成
- Thread
- Thread Block
- Grid of Thread Blocks
Thread
一个单独的线程必然属于一个Thread Block, 它有自己的
- thread ID
- program counter
- registers
- per-thread private memory
- inputs
- output
Thread Block
一个Thread Block必然属于一个Grid, 它是一组并发执行的线程的集合,这些线程之间可以通过barrier synchronization和per-Block shared memory互相协同, 它也有一个Block ID用来索引它在Grid中的位置。
1 | dim3 blockDim; |
Grid of Thread Blocks
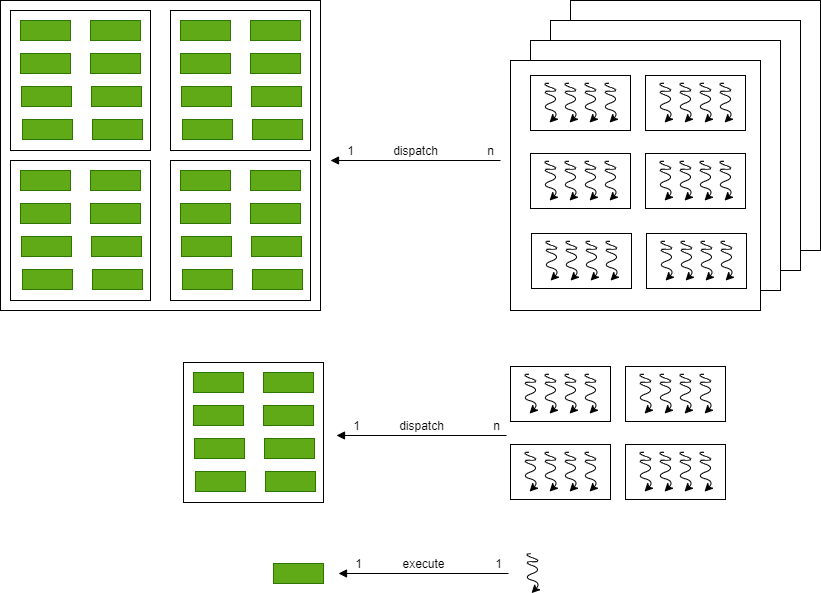
一个Grid由一组执行相同kernel的Thread Blocks组成。可以这样说,一个Grid是所有执行同一个Kernel的线程的集合。
1 | dim3 gridDim; |
CUDA Thread Map
CUDA的threads层级结构可以映射到GPU的processors的层级结构上。
- 一个GPU执行一个或多个grids(kernels)
- 一个SM(Streaming Multiprocessor)执行一个或多个Thread Blocks
- CUDA Cores和一个SM里的其它执行单元(SFU, LDST)执行多个线程
SM执行线程的单位是warp, 一般是32个线程一组,一个warp里的32个线程是真正并行执行的。
CUDA Memory
1 | cudaError_t cudaMemcpy(void *dst, |
除了最后一个参数,其它参数都顾名知意。kind指示内存拷贝的方向:
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
OpenGL Compute Shader Thread Hierarchy
有了前面的CUDA的Thread Hierarchy的了解,OpenGL的Compute Shader的线程层级就好理解了,本质上是一样的。一个OpenGL Compute Shader(cs)就相当于一个cuda中的kernel函数, 这些任务最终被分发到GPU的各个物理核心上去执行。在cs中,单个任务叫做work item, 除了work item之外, 还有以下概念:
- subgroups
也就是warps或者wavefronts或者Compute Units, 它们实际上就是threads, shader cores, cuda cores
- local workgroup
它的大小(维度)在cs中通过layout修饰符指定
1 | layout(local_size_x = 16, local_size_y = 16, local_size_z = 1) in; |
local workgroup相当于cuda的Thread Block
- global workgroup
它的大小(维度)通过OpenGL API设置, glDispatchCompute发起一个或多个compute work groups, 此处的work groups就是local work group
1 | void glDispatchCompute(GLuint num_groups_x, |
global workgroup相当于cuda的Grid
CUDA和Compute Shader变量对比
| type | CUDA | type | Compute Shader |
|---|---|---|---|
| dim3 | gridDim | uvec3 | gl_NumWorkGroups |
| uint3 | blockIdx | uvec3 | gl_WorkGroupID |
| dim3 | blockDim | const uvec3 | gl_WorkGroupSize |
| uint3 | threadIdx | uvec3 | gl_LocalInvocationID |
| - | - | uvec3 | gl_GlobalInvocationID |
| - | - | uint | gl_LocalInvocationIndex |
References: