AMD GPU Vulkan Drivers for Linux
AMD 在 Linux 下维护着两套开源 Vulkan 驱动:
- AMDVLK
- 从闭源 Windows Vulkan 驱动适配而来,主要不同在 shader 编译后端, AMDVLK 使用基于 LLVM 的 LLPC
- RADV
- 包含在 Mesa 内,有两套编译后端: 基于 LLVM 的后端和基于 NIR 的 ACO (AMD COmpiler),但默认的是 ACO
Glossary
GPU Hardware
这里的 hardware block, IP (Intellectual Property) block, controller, processor, engine 基本上都是指一个具有相对独立功能的硬件处理单元。
| Abbr. | Stands for | Description |
|---|---|---|
| GMC | Graphics Memory Controller | 管理 GPU 上不同 IP 如何获取内存 (VRAM) 的控制器,它也提供每进程 GPU 虚拟地址空间的支持(听起来有点像 MMU) |
| IH | Interrupt Handler | GPU 上的中断控制器 |
| PSP | Platform Security Processor | 处理 SoC 上的安全策略,执行 trusted app, 为其它 IP 验证和加载固件程序 |
| SMU | System Management Unit | SoC 的电源管理微控制器,驱动通过这个模块来控制芯片的时钟,电压域,电源轨等 |
| DCN | Display Controller Next | 显示控制器 |
| SDMA | System DMA | 多功能 DMA engine, KMD 利用它完成分页,GPU 页表更新,而且它通过 UMD 暴露给用户态使用 |
| GC | Graphics and Compute | GFX/Compute engine, 这是 GPU 上最大的 IP, 它包含 3D pipeline 和 shader cores |
| VCN | Video Codec Next | Multi-media engine,它处理视频和图像的编解码,通过 UMD 暴露给用户态使用 |
| CP | Command Processor | 包含 GFX/Compute engine 的前端,一批微控制器,包括 PFP,ME,CE,MEC,它们上面运行固件代码,为驱动提供与 GFX/Compute engine 进行交互的接口 |
| CE | Constant Engine | GFX CP 里的一个小处理器,主要用来更新 buffer descriptor 以便异步地将 PFP/ME 使用的 buffer 加载进 cache |
| PFP | Pre-Fetch Parser | GFX CP 里的一个小处理器,需要给它加载 µCode 去执行, 从名字能看出来它是预取 packets 的 |
| ME | MicroEngine | GFX CP 里的一个小处理器,它和 PFP 组成一个 Drawing Engine,可以和 CE 异步执行 |
| MEC | MicroEngine Compute | 微控制器用来控制 GFX/Compute engine 上的 compute queues, Compute Engine 一般有 2 个 MEC, 而且每个 MEC 支持 32 个 HW ring(queue) |
| MES | MicroEngine Scheduler | 一个新的微控制器用来控制 queues, 估计既可以控制 compute queues, 也可以控制 gfx queues, 而且它上面运行的固件可能取代现有的内核 gpu scheduler, 而变成 firmware-based scheduling 😃 猜 |
| RLC | RunList Controller | 又一个 GFX/Compute engine 里的微控制器,用来处理 GFX/Compute engine 内部的电源管理,至于名字是历史遗留,与它的功能没有毛关系 |
Driver
| Abbr. | Stands for | Description |
|---|---|---|
| KIQ | Kernel Interface Queue | KMD 的一个控制队列,用来管理 GFX/Compute engine 上的其它队列 |
| IB | Indirect Buffer | 某个特定 engine 的 command buffer, 通常不是直接将命令写入硬件 queue 里,而是先将命令写入一块内存,然后再将内存的地址写入硬件 queue |
| HQD | Hardware Queue Descriptor | kernel queues 或 user queues 将“映射”到一个 HQD, 一个 HQD 可能就是一个 MMIO 地址寄存器。kernel queues 和 user queues 映射的区别是, kernel queues 总是静态地映射到一个 HQD, 而 user queues 由 MES 动态地 映射到剩余的所有其它 HQDs |
| MQD | Memory Queue Descriptor | 定义 queue 的状态,包括 GPU virtual address, doorbell 等,驱动为每个它创建的 queue 设置一个 MQD, MQD 被交给 MES firmware 去映射 |
| KFD | Kernel Fusion Driver | AMD APU 芯片的内核驱动, 主要用于 HSA 架构的芯片 |
| KGD | Kernel Graphics Driver | AMD GPU 芯片的内核驱动, 主要用于独立显卡和 OEM 上的 GPU 芯片 |
| RAS | Reliability, Availability, Serviceability | AMDGPU 驱动的一个功能特性,帮助错误检测上报,错误处理和调试 |
AMDVLK
AMDVLK 的 README 有一张架构图, 非常清晰地展示了整个驱动包含的组件和层次结构。
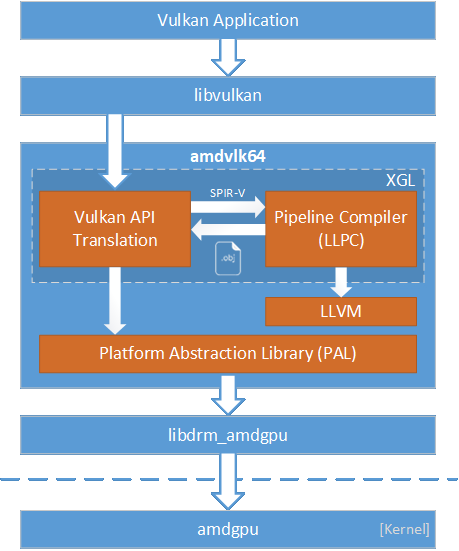
AMDVLK 驱动由 5 个代码仓库构建:
- LLVM
- XGL Vulkan API Translator
- LLPC LLVM-based Pipeline Compiler
- GPURT GPU Ray Tracing Library
- PAL Platform Abstraction Library
其中 XGL, LLPC, GPURT 都与 PAL 有关联。
RADV (Radeon Vulkan)
RADV 和其它 Mesa 的 GPU UMD 一样都是使用 libdrm 库与 KMD 打交道,但后来为了GPU 虚拟化(amdgpu-virto) 支持 Native Context 将大部分 libdrm_amdgpu 库的函数换成了 ac_drm_ 开头的函数, 后来为了GPU 虚拟化(amdgpu-virto) 支持 Native Context 也对 ac_drm 函数接口进行了的修改。 经过这两次修改,RADV 使用的 libdrm_amdgpu 函数基本分为两类:
- 直接调用型
- "inline"型
| Function | IOCTL CMD | Read/Write |
|---|---|---|
| ac_drm_bo_set_metadata | GEM_METADATA | RW |
| ac_drm_bo_query_info | GEM_METADATA, GEM_OP | RW |
| ac_drm_bo_wait_for_idle | GEM_WAIT_IDLE | RW |
| ac_drm_bo_va_op_raw | GEM_VA | RW |
| ac_drm_cs_query_reset_state2 | CTX | RW |
| ac_drm_cs_query_fence_status | DRM_IOCTL_AMDGPU_WAIT_CS | N/A |
| ac_drm_cs_submit_raw2 | CS | RW |
| ac_drm_query_hw_ip_count | INFO | W |
| ac_drm_query_hw_ip_info | INFO | W |
| ac_drm_query_firmware_version | INFO | W |
| ac_drm_query_uq_fw_area_info | INFO | W |
| ac_drm_read_mm_registers | INFO | W |
| ac_drm_query_info | INFO | W |
| ac_drm_query_sensor_info | INFO | W |
| ac_drm_query_video_caps_info | INFO | W |
| ac_drm_query_gpuvm_fault_info | INFO | W |
| ac_drm_vm_reserve_vmid | VM | RW |
| ac_drm_vm_unreserve_vmid | VM | RW |
关于 libdrm_amdgpu 里的函数,其实还有一类,就是 AMDVLK 用到的,而 RADV 没有用的:
- amdgpu_bo_list_create
- amdgpu_bo_list_create_raw
amdgpu (KMD)
Kernel Queue
- ring buffer 是由 kernel 申请的,它的 GPU Virtual Address Space (VMID) 是
01
2
3
4
5
6
7
8
9
10
11
12
13
14
15/* Allocate ring buffer */
if (ring->ring_obj == NULL) {
r = amdgpu_bo_create_kernel(adev, ring->ring_size + ring->funcs->extra_bytes,
PAGE_SIZE,
AMDGPU_GEM_DOMAIN_GTT,
&ring->ring_obj,
&ring->gpu_addr,
(void **)&ring->ring);
if (r) {
dev_err(adev->dev, "(%d) ring create failed\n", r);
kvfree(ring->ring_backup);
return r;
}
amdgpu_ring_clear_ring(ring);
} - 不支持 preemption